UFLDL教程总结(5) 从self-taught到deep networks
把Autoencoder堆起来,再加个softmax层,就是Deep Network了.
这样之前的Autoencoder的训练过程叫做预训练(Pre-training),最后如果把整个网络用BP和数值优化方法训练,那后面这一步就叫做精调(Fine-tuning).
层数增多后,网络就能表示更复杂信息,因为隐藏层都是前一层的非线性变换.为啥是非线性的?前一层的输入经过一组系数后,得到的是一个线性组合,给这个线性组合加上一个非线性的激活函数,就成非线性表达了.
层数增多的缺点是:模型表达能力很强,但如果训练数据不足时就会过拟合;局部最小值会使数值优化方法不能得到最优解;层数多会梯度扩散(Diffusion of gradients),从后向前传递回去的误差会越来越小.
所以要pre-training,也就是贪婪地逐层训练.主层训练利用了无标签数据,用它们无监督的学习特征,于是整个模型的初始值会比随机初始好,于是数值优化的结果也就好了.
下面这个4层网络的中间两个隐藏层就是用Autoencoder贪婪逐层训练得来的.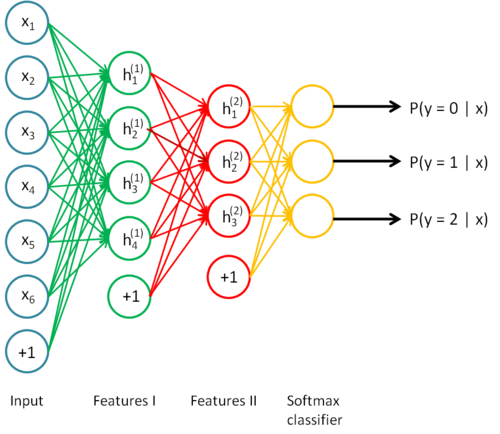
n层网络的精调,使用Backpropagation
- 1 用正向传导计算\(L_{nl}\)层的激活输出,\(nl\)是层数.
- 2
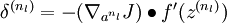 ,计算最后一层误差,也就是softmax层的误差.
,计算最后一层误差,也就是softmax层的误差. - 3 对于\( l = n_l-1, n_l-2, n_l-3, \ldots, 2\),从后往前开始计算各层各单元的误差
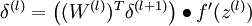 .
. - 4 误差函数是
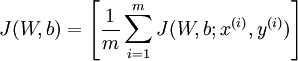 ,
,
关于各参数的梯度是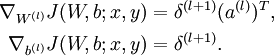
实验
还是用MNIST,用了两个隐藏层,每个都是用Autoencoder训练.接着训练一个softmax层.最后把所有层用BP精调.