变分贝叶斯推断
参考:
http://people.inf.ethz.ch/bkay/talks/Brodersen_2013_03_22.pdf
http://www.inference.phy.cam.ac.uk/mackay/itprnn/ps/341.342.pdf
An approximate answer to the right problem is worth a good deal more than an exact answer to an approximate problem.
贝叶斯推断是一个利用数据从先验概率得到后验概率的推断过程,公式如下.
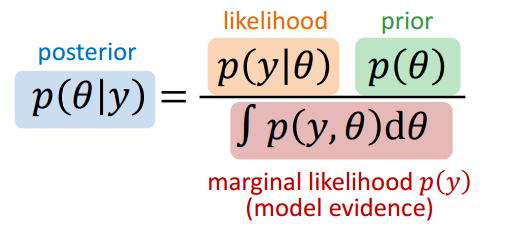
实际上这个很难求出,因为RHS的分母不容易求解.所以一般有两种推断方法,一种叫做Stochastic approximate inferencem,比如采样就是其中之一.它是设计一种方法,直接从\(p(\theta|y)\)里采样,再计算所得结果的统计特征.这种方法可用但计算量太大.第二种称为Structural approximate inference,变分贝叶斯推断属于这个.寻找一个函数\(q(\theta)\),作为\(p(\theta|y)\)的”代理”,使得它们最大程度接近,然后计算\(q(\theta)\)的统计特性即可.
先介绍Laplace Approximation.
Laplace Approximation
计算概率时经常碰到这种情况,分母(归一化项)无法得到,如下式,

比如上面的贝叶斯推断就面临这个问题.

虽然无法得到\(p(y)\),但是由于\(p(y)\)是\(p(y,\theta)\)对\(\theta\)的积分.所以寻找一个”代理”函数,假设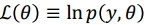 ,并且写出二阶泰勒展开(并认为这个函数一阶导为0),如下式.
,并且写出二阶泰勒展开(并认为这个函数一阶导为0),如下式.
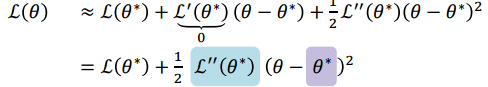
这个式子和高斯分布取对数很接近,
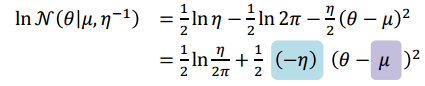
对应地,把”代理”函数设为高斯分布,众数(mode)就是泰勒级数展开点,标准差为众数点负二阶导.然后估计出这个分布的参数就能完成推断.
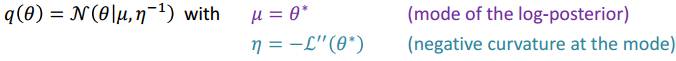

Variational Bayesian inference
和Laplace差不多,VB想要寻找一个函数,让它和真实的后验概率最大程度接近.两个分布之间的距离当然就是KL距离,所以肯定要推出一个KL距离的式子.

也就是

让第二项Free Energy最大可使第一项KL距离最小.
在下一步计算之前,先解释mean-filed假设,其实也就是假设各分量独立.
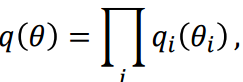
Free Energy这一项引入mean-filed假设后可以表示如下,
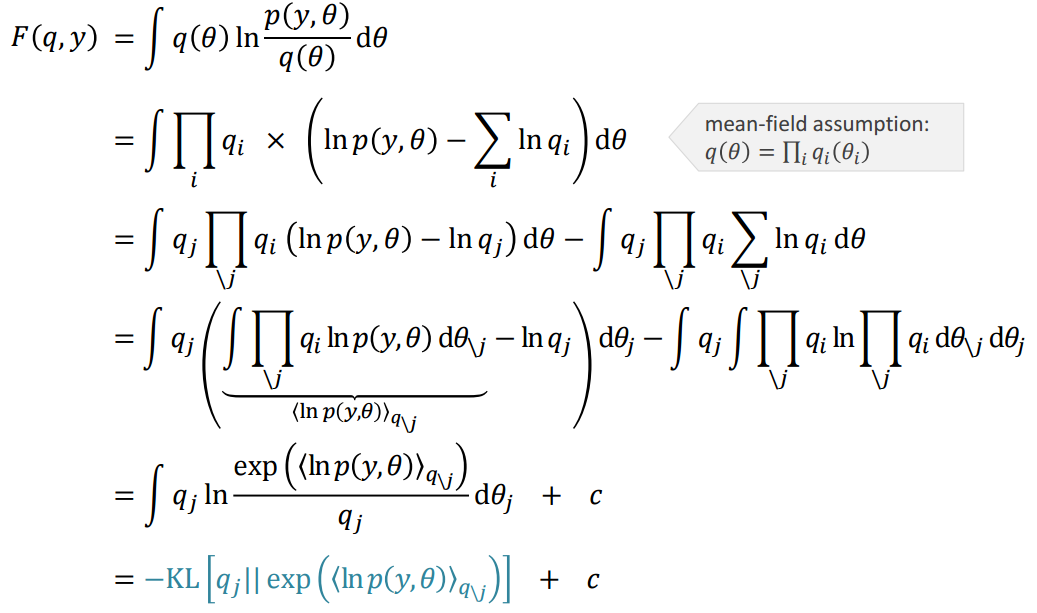
让Free Energy最大的\(q(\theta)_j\):
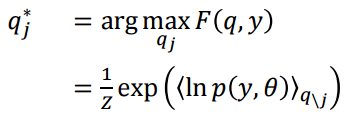
变分推断步骤:
- 用先验概率初始化后验概率的估计\(q(\theta_j)\)
- 循环所有参数,用当前估计去修正后验.
- 循环至收敛.