[论文笔记]Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
使用过卷积神经网络(CNN)的人都知道,训练数据的维度都是相同的,这样经过卷积池化后,得到的特征维度才能相同,进而才能将特征输入到分类器中训练分类器.输入维度相同这个限制太大了,这篇文章主要针对这个缺陷进行了改进,具体地就是加入了空间金字塔池化(Spatial Pyrimid Pooling),使得不同维度的输入最后都能得到相同维度的输出.
简介
作者认为,传统CNN所需要的固定维度输入这一限制,是造成任意尺度的图片识别准确率低的原因.传统的CNN需要先对训练图片进行处理,使其维度相同.具体有两种做法,裁剪(cropping)和扭曲(warping).如下图.
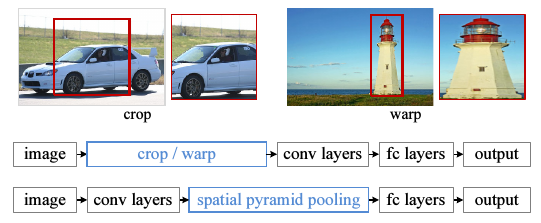
缺点是:裁剪了的区域可能并不包含整个物体,而扭曲则会带入几何方面的失真.另外,即使是裁剪和扭曲,我们仍然是认为规定了一个输入尺度,而真实的物体尺度很多,这个固定维度的输入直接忽略掉了这一点.
为何非要给CNN限制一个固定维度的输入?作者说,CNN就分两块,卷积层和全连层(fully-connected layer),卷积层的输出是特征图(feature map),这个特征图反映出了原始输入图片中对filter(卷积核)激活的空间信息.卷积这一步是不需要固定大小的.是最后的全连层带来的这个限制.
作者针对这个问题,提出了在CNN的最后一个卷积层之后,加入一个SPP层,也就是空间金字塔池化,对之前卷积得到的特征进行”整合”(aggregation),然后得到一个固定长度的特征向量,再传到全连层去.如下图.

SPP是词袋模型(Bag-of-Words)的扩展.为什么说是扩展?词袋模型没有特征的空间信息(就像它只能统计一个句子中每个单词的词频,而不能记录词的位置信息一样).在深层CNN里加入SPP会有3个优势: 1) 相比之前的滑动窗池化(sliding window pooling),SPP可以对不同维度输入得到固定长度输出. 2) SPP使用了多维的spatial bins(我的理解就是多个不同大小的窗),而滑动窗池化只用了一个窗. 3) 因为输入图片尺度可以是任意的,SPP就提取出了不同尺度的特征.作者说这3点可以提高深度网络的识别准确率.
SPP-net既然只在网络的最后几层(深层网络)中加入,而本质上就是池化,所以它可以加入到其他CNN模型中,比如AlexNet.作者的实验表明,加入了SPP的AlexNet效果确实提升了.作者认为SPP应该能提升更复杂的网络的能力.
##原理
###卷积和池化
一个CNN里,除了最后的全连层,前面的卷积层和池化层其实都可以看作是卷积运算(都是滑动窗).卷积操作得到的结果(feature map)基本上和原始的输入图片是一个比例(如果不懂CNN就去看UFLDL教程吧).feature map的意义是,它不但表示了响应的强度,也记录了响应的位置信息.
对之前卷积得到的特征进行”整合”(aggregation),然后得到一个固定长度的特征向量,再传到全连层去.如下图.

上图可视化了卷积和池化提取的特征的意义,就是feature map的意义,feature map上的每一个点(或者某一个区域)对应这实际物体的某种形状,也就是某种模式了.
###SPP怎么做
若输入维度不同,卷积层会输出的不同大小的feature map.其实把BoW用在这些feature map上已经可以解决固定输出的问题了,但SPP使用local spatial bins来做池化,保留了空间信息,是一个提升.SPP的原理其实就一句话,SPP的spatial bins(也就是池化时候的窗口大小)是和输入图片的大小成比例的,所以spatial bins的数目也就固定下了,和输入大小无关.原理是下图.无论feature map的大小是多少,总是可以把一个feature map分成4x4,或者2x2,或者1x1,只是每一个小方块大小不一样.
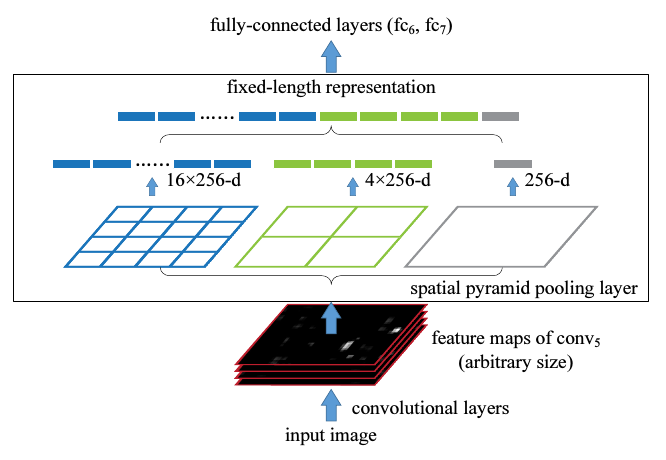
具体地,在一个CNN里,把最以后一次池化层去掉,换成一个SPP去做最大池化操作(max pooling).如果最后一次卷积得到了k个feature map,也就是有k个filter,SPP有M个bin,那经过SPP得到的是一个kM维的向量.我的理解是,比如上图中第一个feature map有16个bin,一共有256个feature map,每一个经过16个bin的max pooling得到16个数,那256个feature map就是16x256的向量了.SPP的bin大小可以选择多个,所以经过SPP还能产生4x256,1x256维的向量.
我们可以对不同比例,不同大小的图片进行处理,而且使用同一个CNN,只是对不同大小的图片,在最后的SPP里,bin的大小不同,但最后得到的特征确实相同维度.这样,我们把一张图片resize成不同尺度,放到同一个CNN里训练,就能得到不同尺度下的特征,就和SIFT类似了.
##训练
虽然SPP理论上可以直接用BP来训练参数,但现有的使用了GPU的CNN工具,比如caffe和cuda-caffe都只能以固定大小的图片作为输入.作者使用了caffe,但是用了一些技巧来实现SPP的训练.
###单一大小训练
如果一个图片大小固定,比如224x224,那么我们就能计算出它的池化窗口(bin)的大小.比如经过第五个卷积层conv5之后得到的feature map是a x a(13x13),如果金字塔大小n x n,那么窗口大小就是ceil(a / n), 步长是floor(a / n).我们可以用\(l\)个不同大小的窗口,比如3x3, 2x2, 1x1.然后把这\(l\)个输出连接起来,送入之后的全连层.下图是这样3个窗口和最后的全连层的的配置文件.

多个大小训练
我们再考虑一种输入大小(180x180),两种大小也算是”多个大小训练”啊.这个180x180的直接取224x224图片的按尺度缩放图片,这两张图除了解析度不同别的都相同.180x180的图片经过第五层卷积后的feature map是10x10,这时我们依然用刚才的公式,窗口大小就是ceil(a / n), 步长是floor(a / n),这样的话后得到的特征长度与之前的224x224的特征长度相同.举个例子,如果金字塔是3*3,即n=3,那么对于第一种大小,窗口长为5,步长4,第二中大小,窗口4,步长3,如下图.
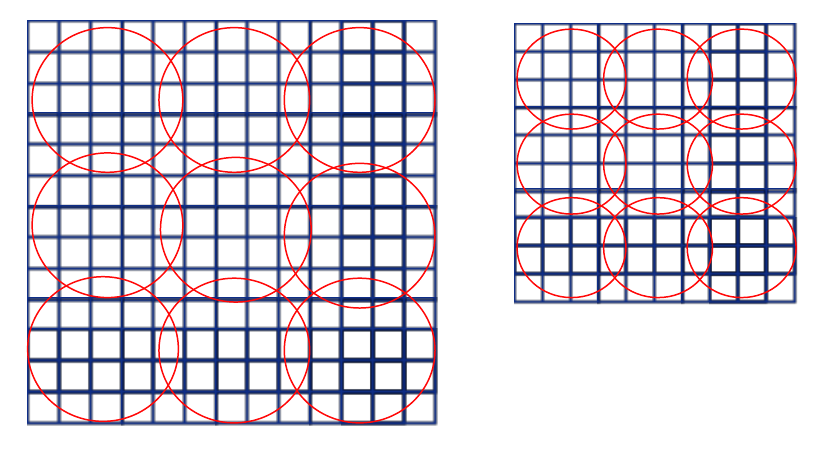
红色区域代表窗口,经过最大池化后,两张图得到的特征向量长度均为3x3=9.所以180的网络和224的网络参数完全一样,于是SPP训练阶段,对于这两种网络只要共享参数即可.
实际训练时,为了减少不停转换网络带来的开销,需要使用全部数据一次训练一个网络,然后再换成第二个,作为一次迭代.所以作者根本没有实现训练不同大小输入的CNN的BP算法,只是针对各种各样大小不同的输入,定义出不同的网络,但这些网络实际上参数都相同,于是就可以用现有工具来训练.
这个是训练阶段,需要不停转化网络,当训练好模型用于测试时,只要输入图片就行了.
SPP-NET图像分类实验
作者设计了一系列对比实验,证实SPP-NET可以对其他CNN模型能力进行提升.
训练的时候先把原始图像缩放到短边长256,然后从中心或者是4个角上裁剪一个224x224,之后又做了Data augmentation,镜像和RGB上的变换,以及Dropout,就是重复了AlexNet那篇论文上的实验.
1. Baseline
使用了3种网络结构,ZF-5, Convnet*-5, Overfeat-5/7.
2. 多级Pooling提升性能
Baseline里的训练测试图片维度都224x224,测试时用的是10-view,就是中间加4个角再镜像的十个224x224.把最后一个卷积层之后的Pooling换成SPP,并用了{6x6, 3x3, 2x2, 1x1}共50个bin,这样就降低了top-1,top-5错误率.为了证明性能提升不是因为模型参数多了,他还使用了30个bin的SPP,还是提升了.
3. 多级训练提升性能
使用了两个大小,224和180,测试依然用224.另外作者还尝试在[180, 224]之间随机挑一个大小来训练.
4. 用整张图片来测试
把图片缩放到短边256,然后直接输入到SPP-NET网络里去计算.对比实验是使用中心裁剪出的224x224大小图片计算.效果有提升,但不如10-veiw的结果.但依然是有意义的,第一,在10-view上加上full-view可以提升性能.第二,使用full-view有方法学上的意义,与传统SIFT方法一致.第三,易于在图片检索中使用.
5. 在feature map上使用Multi-view测试
这个比较复杂.首先测试阶段,把图片短边缩放到s,比如256,然后通过卷积层计算feature map,同样也使用镜像图片作为输入计算另一些feature map.View是指,在原始图片上的一个view(或者叫窗口),由于CNN保留了空间信息,所以能够在feature map上找到这个原始图片上的窗口的对应位置.然后使用SPP对这个窗口在feature map上的对应位置做pooling,再把结果送入全连层计算这个窗口的softmax得分.Multi-view是指,还是以前的standard 10-view,就是中心及角上的224x224窗口,我们在最后的feature map中找到这些窗口的对应位置,只对这些位置做pooling.
进一步,作者把测试图片缩放成了不同大小,短边s={224, 256, 300, 360, 448, 560},窗口依然是224x224,但用了18个窗口(在每条边的中心处多了一个窗口,再加上镜像共8个).又进一步提升了性能.
我觉得这个Multi-view可以用在object detection上.只对感兴趣窗口(object)对应的feature map进行pooling,然后对object训练SVM.
SPP-NET物体检测实验
R-CNN进行物体检测的方法是,首先从每张图片选出2000个候选窗口,然后把窗口变形到227x227,把每个窗口送入网络计算特征,然后训练SVM进行二分类.R-CNN效果很好,但是对每一张图片的2000个窗口都要送进卷积网络计算,很费时间.
SPP-NET可以直接对一张整图计算feature map(以及不同尺度的这张图片),然后只需要在feature map的不同区域进行SPPooling即可,没有了像R-CNN的从头卷积那一步,如下图.
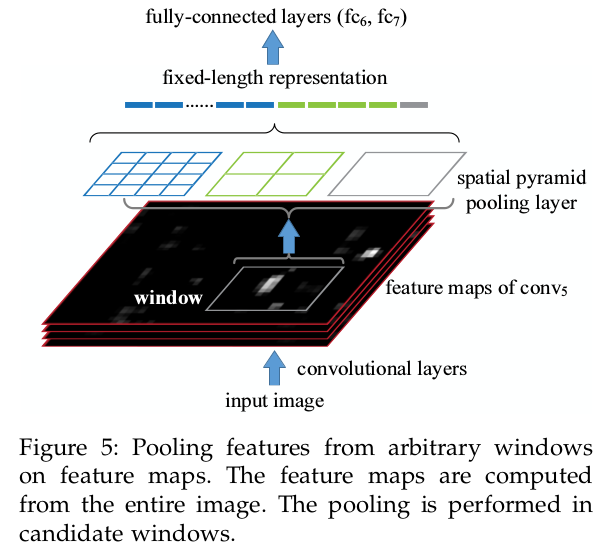
作者还说像其它方法,比如DPM,SS等,虽然都从feature map来选择窗口,但这个窗口是预先固定的,而SPP不需要(这点不理解,估计一会儿会讲清楚).
检测算法
使用Selective Search产生2000个窗口,将图片短边缩放至s,使用网络对图片计算feature map.对每一个候选窗口,在feature map上使用4个空间金字塔{1x1,2x2,3x3,6x6}50个bin,于是可以产生256*50维特征,然后用这个特征训练SVM,每个图像类别训练一个SVM.
训练SVM得构建正例和负例.最后这20个SVM可以用来计算物体属于每个类别的得分.
把输入图片的尺度增加,短边s分别是{480, 576, 688, 864, 1200},分别计算feature map.现在有很多组feature map了,怎么提取候选窗口的特征?一种方法当然是都提取.作者用的是,对每一个候选窗口,只选一个尺度对应的feature map,这个尺度应该使得经过相同的尺度变换的候选窗口的像素数接近224x224.然后就pool这一个feature map.
这个预训练好的网络也可以进行fine-tuned,但只调整全连层的参数.方法就是在最后一个全连层之后再加一个21路的全连层,20个类别,还有一个是负例的类别.精调细节不说了.这一阶段还做了对预测窗口的post-precess.
结果
精调过的网络效果较好.原因是pre-trained的网络使用的图片区域,检测的时候用的feature map区域.
模型复杂度和运行时间
完胜R-CNN.
模型组合
两个SPP-NET组合提升mAP.
ILSVRC 2014结果
PS
为什么固定大小输出的CNN一直没有被应用?这次才换了个名字叫做SPP-NET. Ng 12年就在语音上使用了一个固定维度输出的CNN(论文),和这个思想几乎一样.