[论文笔记] ImageNet Classification with Deep ConvolutionalNeural Networks
cuda-convnet
这篇文章提出的CNN模型在imagenet 2012比赛中得了冠军,之后这个CNN就用作者的名字叫做AlexNet了.Alex还写了一个CNN工具cuda-convnet用来跑它的模型,这个工具实用又相比caffe较轻量级.看cuda-convnet文档的时候看到一个有意思的,记录一下.
Locally-connected layer with unshared weights
This kind of layer is just like a convolutional layer, but without any weight-sharing. That is to say, a different set of filters is applied at every (x, y) location in the input image. Aside from that, it behaves exactly as a convolutional layer.
Here’s how to define such a layer, taking the conv32 layer as input:1
2
3
4
5
6
7
8
9
10
11[local32]
type=local
inputs=conv32
channels=32
filters=32
padding=4
stride=1
filterSize=9
neuron=logistic
initW=0.00001
initB=0
Aside from the type=local line, there’s nothing new here. Note however that since there is no weight sharing, the actual number of distinct filters in this layer will be filters multiplied by however many filter applications are required to cover the entire image and padding with the given stride.
字面上来理解,以前CNN里的一个filter可以用在一整张图上,经过卷积得到一个feature map,这个就相当于是shared weights了,因为这个filter实际上被用了好多次.unshared weights filter就是由一组filters来产生一个feature map,一组指的就是一个filter窗口经过步长移动后,在新的位置上的其实是一个新的filter,所以一组的大小就是由窗口的大小和步长来确定的,它需要覆盖住整个输入(其实和之前的卷积filter没区别,只是这次要计算的参数就多了).
ReLU Nonlinearity
这是一个新的激活函数,地位就和NN里的sigmoid函数一样,不过这个很特殊,从图上就能看出.
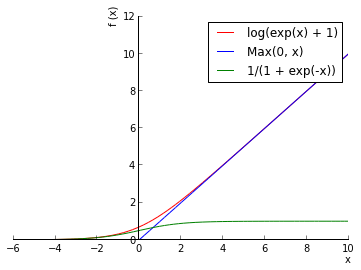
以前我们用sigmoid做激活函数,因为sigmoid的输出在[0, 1]之间,可以看做概率值.ReLU的输出是0到正无穷,可以用来建模实数输出.另外,ReLU的梯度不会消失,实际上它的梯度就是0或者1,这样整个网络收敛快了.ReLU具体参考这里.
Local Response Normalization
这个东西就是对同一个输入(图片,或者图片卷积后的feature map)产生的好多feature maps做一个归一化,作为输出.具体地,就是在同一个空间位置(spatial position)(x, y)上,比如这个位置上如果有32个feature map,那么第7个feature map上的输出实际上考虑了从第5个到第9个feature map上同一个位置上的输出,对这些输出做了一个归一化.下面式子里的N指当前输出的总的feature map个数(对应着上层filters的个数),式子里的超参数k,alpha,beta都需要通过验证集调参得到.
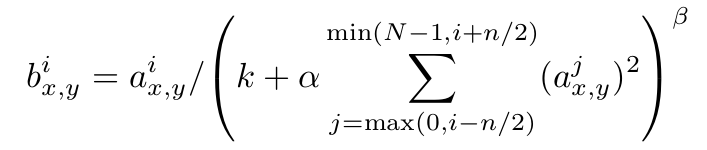
文中说这种想法由真实神经元中的lateral inhibition现象而来,可以使不同的filter产生出的feature maps中较大激活的输出之间产生竞争(大概经过训练后会得到更好的特征吧).
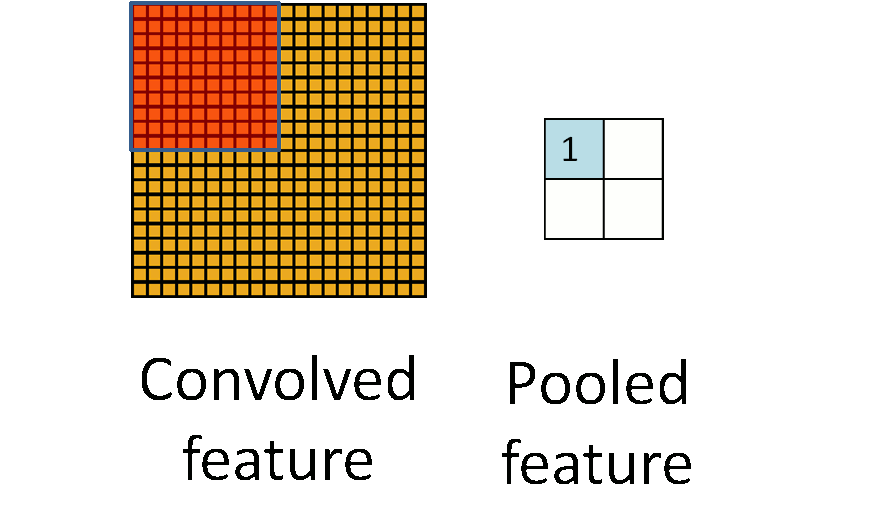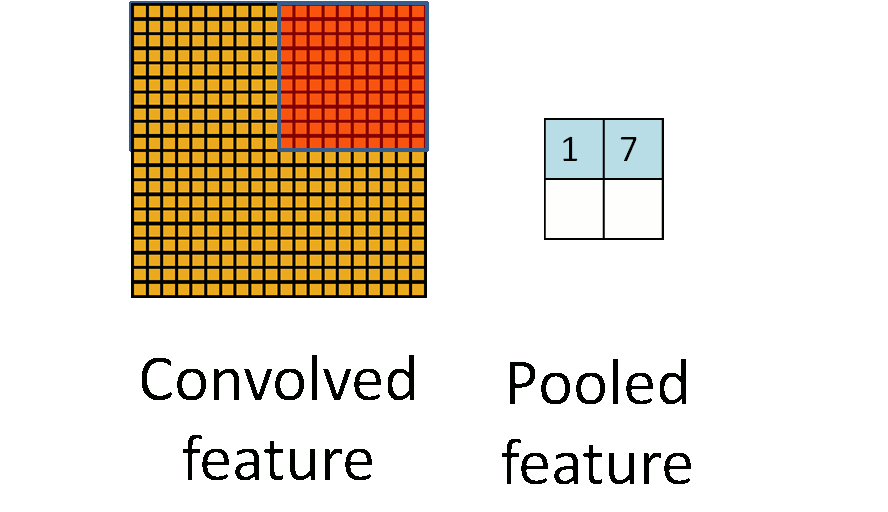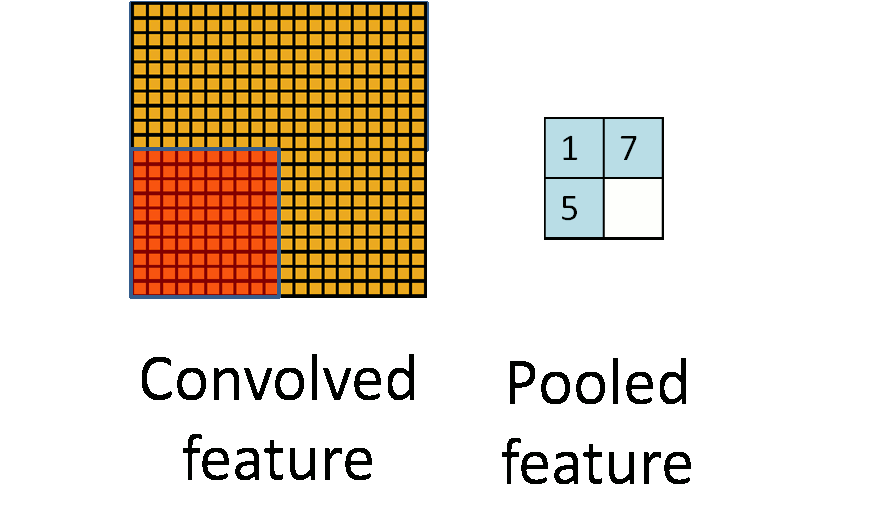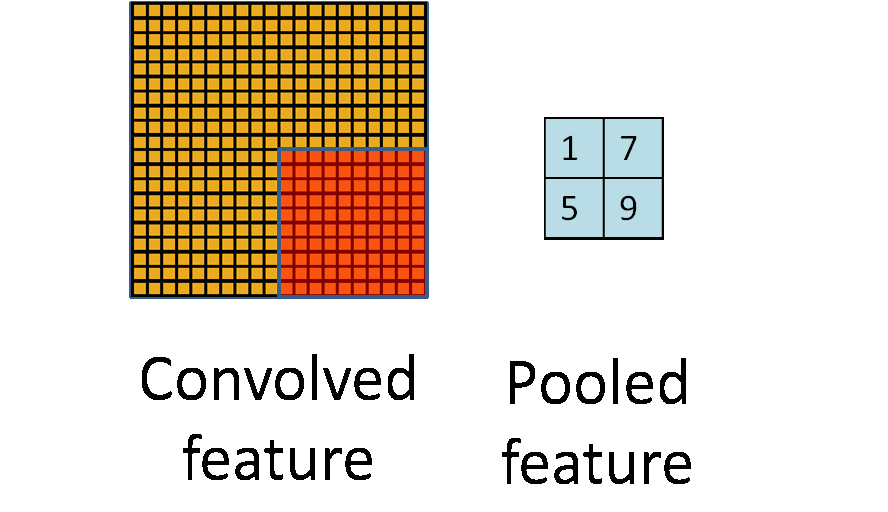
Overlapping Pooling
这个和SPP里的池化窗口类似,即以前出的CNN池化窗口是不重合的,像这张图.这里的池化窗口也有一个步长,之间可以重叠(都到这一步了你怎么不直接用它来做不同维度输入得到相同大小输出的SPP呢你可是大牛啊).
Overall Architecture
整个网络共8层,前5曾卷积网络,后3层全连网络,最后接一个1000路softmax分类器.这图分了上下两部分,代表两个GPU,各训练一半的filter和神经元.不过两个GPU会在第2,3层通信,作者说这是一个trick.这图里没有把池化和归一化操作画成图,池化只在第一层,第二层,第五层之后做了.
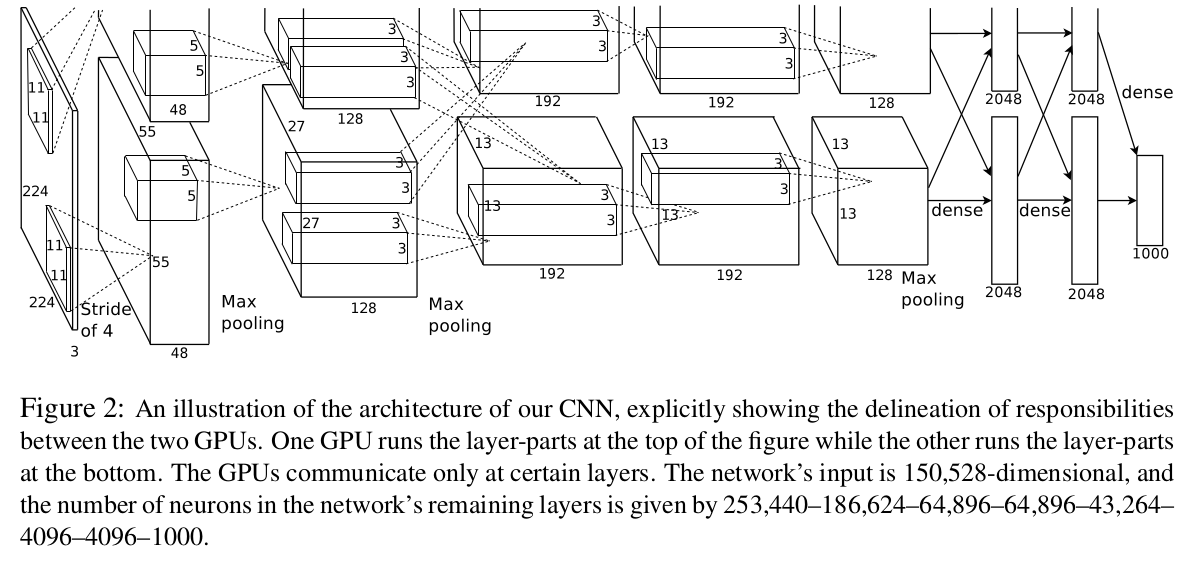
从图上看,输入是224x224x3,第一层是96个filter,两个GPU各接受48个,filter大小是11x11x3,所以每一个GPU,第一层的feature map大小是48x55x55(55是卷积的时候用了步长为4得出的,原图片作为输入的时候肯定补0了,这是cuda-convnet自己做的).然后这个图就看不懂了.输入经过卷积后每一个GPU的输出是48x55x55,然后是最大池化,应该是变成了48x27x27再输入到第二层网络(当然,还要normalization一下),但这个图上没把pooling层画出来,看不到这个48x27x27,到是有一个128x27x27,怎么回事?128不应该是再下一层的filter个数吗?这里只能先放着吧.
Data Augmentation
首先做了好多裁剪和镜像.
还有就是对RGB做了处理.具体是对每一张图片上的每一个像素点,它对应了一个3维向量(RGB的3个值),那么对整个ImageNet,做由每一个像素点组成的矩阵的PCA,像素点组成的矩阵的协方差矩阵是3x3的,所以能计算出3个特征值和特征向量.然后改变以前的RGB三维向量,具体就是在以前每个像素点的RGB三维向量\([I_{xy}^R, I^G, I^B]\)(xy是像素坐标)上加这么个东西.
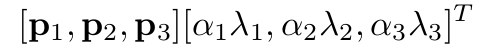
其中p1,p2,p3是特征向量,lambda是特征值,alpha是一个0均值,标准差0.1的高斯分布随机值.
Dropout
怎么在训练一个模型的时候,能训练出多个模型,进而使用多个模型来预测,降低测试误差?Hinton想出的办法就是这个Dropout,把神经元的输出以0.5的概率置零,相当与扔掉了,被扔掉的神经元在前馈和反馈中都不起作用.所以每当有一个新输入时,由于Dropout的随机性,相当与在训练一个新的网络,但是这所有的网络是共享参数的.
这种策略减少了神经元之间的互相影响的一些现象,是的神经元不能依赖某一个特别的神经元是否出现,这样模型就能训练出更好的特性.
测试的时候就不dropout了,而是给每个神经元输出值乘以0.5,作为引入了dropout后预测分布的均值的估计.
作者在CNN网络之后的全连网络里引入了Dropout(原来那两个全连网络是干这事的).Dropout使迭代次数几乎翻倍才达到收敛,不过很好的减少了过拟合.
讨论
最后作者除了秀了一下AlexNet在各种数据库上的成绩,还贴了张挺惊人的图.

在1000路softmax分类器之前有4096个神经元输出,一张图片输入进网络走到这一步就变成了一个4096维的向量,第一列是5张测试图片,而其它几列则是整个数据集中的图片产生的4096维向量,与测试图片的向量欧式距离最近的6个.作者说,给这4096维的向量做个自动编码器映射成二维向量后,估计又能当图片检索来用了.